#12 ️ Modular RAG: Crafting Customizable Knowledge Retrieval Systems
Imagine building a team of experts, each specializing in a unique area, working together seamlessly to solve a complex problem.
Imagine building a team of experts, each specializing in a unique area, working together seamlessly to solve a complex problem. This is what Modular RAG (Retrieval-Augmented Generation) aims to achieve in AI. Instead of relying on a single retrieval and generation approach, Modular RAG combines multiple retrieval, processing, and generation modules to create a dynamic, adaptive system. In this chapter, we’ll explore how to design, implement, and optimize Modular RAG systems, making AI solutions more robust, accurate, and versatile.
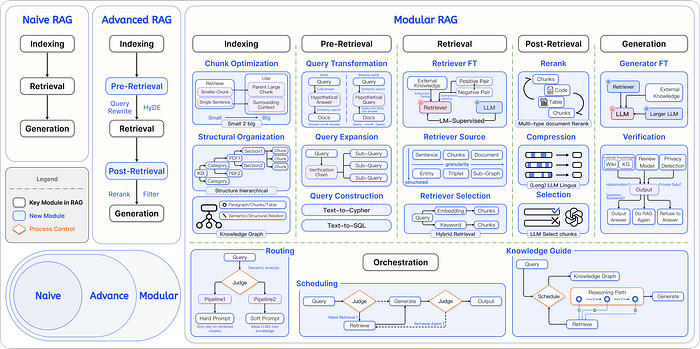
https://arxiv.org/html/2407.21059v1
1. What is Modular RAG? 🧩
In a traditional RAG setup, the system typically follows a single flow: it retrieves information based on the query, processes it, and generates a response. Modular RAG, however, is built with different modules or components that handle specialized tasks. These modules can include:
-
Contextual Retrieval Module: For retrieving information based on context.
-
Domain-Specific Module: Optimized to fetch data for specialized fields, such as healthcare, law, or finance.
-
Real-Time Data Module: Fetches up-to-date information from APIs, databases, or web sources.
-
Post-Processing Module: For refining, filtering, or ranking retrieved data before generation.
These modules work in unison to create a holistic response, each adding its expertise to the final answer.
2. Designing Modular RAG Architectures 🎨
Designing a Modular RAG system starts with identifying the specialized needs of your application. Let’s look at some design principles:
2.1 Component Breakdown 🛠️
Each component of the Modular RAG system should have a clear, unique purpose. Here’s how to think about it:
-
Retriever Module: Set up multiple retrievers optimized for different types of data (text, images, real-time information).
-
Filter Module: Use filters to refine retrieved data, such as by date, relevance, or quality.
-
Ranking and Re-ranking Module: Rank results based on relevance to the query and refine the top choices.
Example Code: Building a Modular RAG Retriever
Let’s implement a simple multi-retriever setup using LlamaIndex.
from llama_index import GPTVectorStoreIndex, SimpleWebPageReader, DocumentRetriever
# Define a text retriever
text_retriever = GPTVectorStoreIndex()
# Define a real-time data retriever (e.g., live news or weather)
class RealTimeRetriever:
def retrieve(self, query):
# Placeholder for real-time retrieval logic
return f"Real-time data for query: {query}"
# Define a document retriever for structured documents
doc_retriever = DocumentRetriever(index_path="documents_index")
# Define a modular retrieval function
def modular_retrieve(query):
results = []
results.extend(text_retriever.retrieve(query))
results.append(RealTimeRetriever().retrieve(query))
results.extend(doc_retriever.retrieve(query))
return results
query = "Latest news on renewable energy"
modular_results = modular_retrieve(query)
print(modular_results)Explanation: Here, we’ve set up a text_retriever, a RealTimeRetriever, and a doc_retriever. Each module retrieves information from different sources, allowing the system to combine responses for a more comprehensive answer.
3. Integrating and Orchestrating Modules 🎻
The next step is to orchestrate the modules to work together effectively. This is where an orchestration framework, such as LangChain, can play a vital role in managing the flow between modules.
3.1 Using LangChain for Module Coordination
LangChain can coordinate between retrieval modules, filtering modules, and post-processing modules. For example, if a user asks a question related to real-time events, LangChain can prioritize the RealTimeRetriever module. Otherwise, it can fall back on the text_retriever or doc_retriever.
from langchain import SequentialChain, PromptTemplate
# Define prompt templates for each module
general_prompt = PromptTemplate("Find general information on {topic}.")
real_time_prompt = PromptTemplate("Fetch live updates on {topic}.")
specialized_prompt = PromptTemplate("Get structured data for {topic}.")
# Use a sequential chain to integrate modules
module_chain = SequentialChain(
prompts=[general_prompt, real_time_prompt, specialized_prompt]
)
# Example usage
user_query = "COVID-19 updates"
response = module_chain.run({"topic": user_query})
print(response)Explanation: This code coordinates the retrieval and prompt handling for each module. By using a sequential chain, the response can flow through each module based on the topic, ensuring the best module is chosen.
4. Optimizing Modular RAG for Performance and Accuracy ⚙️
With multiple modules in play, performance optimization is essential. Here are some strategies:
4.1 Dynamic Module Selection 🌐
Instead of using all modules for every query, select modules dynamically based on the query’s needs.
Example Code: Dynamic Selection Based on Query Type
def select_modules(query):
if "real-time" in query or "latest" in query:
return [RealTimeRetriever()]
elif "structured" in query:
return [doc_retriever]
else:
return [text_retriever]
# Dynamically select modules based on query type
selected_modules = select_modules("Get latest weather updates")
results = [module.retrieve("Get latest weather updates") for module in selected_modules]
print(results)Explanation: Here, we dynamically choose which module to run based on keywords in the query, reducing unnecessary retrieval time and focusing on relevance.
4.2 Parallel Processing 🚀
Parallel processing allows modules to operate concurrently, significantly reducing response time.
Example Code: Parallel Processing with Concurrent Futures
import concurrent.futures
# Define function to run each module in parallel
def run_module(module, query):
return module.retrieve(query)
query = "Global warming effects"
modules = [text_retriever, RealTimeRetriever(), doc_retriever]
# Run modules in parallel
with concurrent.futures.ThreadPoolExecutor() as executor:
results = list(executor.map(lambda m: run_module(m, query), modules))
print(results)
**Explanation**: By leveraging Python’s concurrent.futures, each retrieval module can run simultaneously, improving overall efficiency.5. Use Cases and Real-World Applications 🌍
Modular RAG systems excel in complex, multi-source data environments. Here are some practical applications:
-
Healthcare Knowledge System: Retrieve real-time updates on medical research, structured patient records, and general medical literature.
-
Financial News Aggregator: Combine historical data with live market news and structured financial reports for comprehensive financial updates.
-
Customer Support Bot: Retrieve information from knowledge bases, real-time status updates, and user-specific data, ensuring personalized support.
6. Benefits and Challenges of Modular RAG ⚖️
Benefits:
- Flexibility: Modular RAG enables AI systems to handle diverse queries across different data sources.
- Scalability: New modules can be added as needed, allowing easy expansion.
- Improved Relevance: Each module is tuned to its specific data source, improving the accuracy and relevance of responses.
Challenges:
- Complexity in Orchestration: Managing multiple modules can lead to intricate workflows.
- Performance Overheads: Additional modules may slow down the response time if not optimized.
- Error Handling: Failures in individual modules need careful handling to avoid cascading issues.
7. Summary and Next Steps 🔄
Modular RAG offers a powerful approach to retrieval-augmented generation by combining specialized modules tailored to different types of queries and data sources. This flexibility allows AI systems to deliver richer, more accurate, and contextually relevant answers. However, careful orchestration and optimization are essential to keep performance high.
Recap
In this chapter, we delved into Modular RAG, showcasing how a flexible and component-based approach can transform retrieval systems. By leveraging modular setups that combine dense retrieval, sparse retrieval, and hybrid search, you can create a system that adapts seamlessly to various query types and data sources. Whether it’s navigating legal documents ⚖️, analyzing scientific papers 📄, or assisting with customer support queries 📞, Modular RAG empowers your AI to handle complex information with precision and agility.
In the next chapter, we’ll explore Fine-Tuning LLMs for Precision: Unlocking the Full Potential of AI 🤖🎯, where we’ll refine models for specific tasks, enhancing accuracy and relevance to meet real-world demands. Stay tuned!